| Code: https://github.com/Veri-Code/ReForm |
| Models & Data: https://huggingface.co/Veri-Code |
项目背景
自动形式化将自然语言内容转换为可验证的形式化表示,是学习通用推理的一种富有前景的方法。相比之下,当前基于自然语言的大语言模型缺乏可靠的验证机制。形式化验证器不仅对于提升人类的“韧性”至关重要,而且有助于将人工智能的发展引导至最大化“数学探索”的方向,从而有望使人工智能对人类更加安全友好。
尽管形式化验证通常难以实现,但自动化推理领域的最新进展有望降低其门槛。然而,当前的大语言模型无法独立进行真正的逻辑推理或自我验证,其本质应视为通用的近似知识检索器。鉴于形式化验证器的重要作用,我们致力于探索拓展其能力边界。
代码智能体在人工智能领域引发了广泛关注,其日益增强的问题解决能力可能预示着更广泛的通用智能。得益于大语言模型的最新进展,自动化代码生成已取得显著成效。
然而,确保生成代码的正确性仍然面临着严峻的挑战,尤其在医疗健康、金融、自主系统等安全关键领域。传统的防护措施(如单元测试和人工代码审查)存在着固有局限,例如遗漏边缘情况、难以覆盖所有执行路径、高度依赖专家经验。
相比之下,形式化验证提供了一种基于规则的替代方案。为此,我们提出对自然语言查询及其生成的代码分别独立进行自动形式化,随后验证二者所导出规范的等价性,从而确保代码行为与原始意图的精确对齐。通过对任意代码进行深层次语义理解和详尽的行为刻画,最终实现形式化规范生成。
核心设计
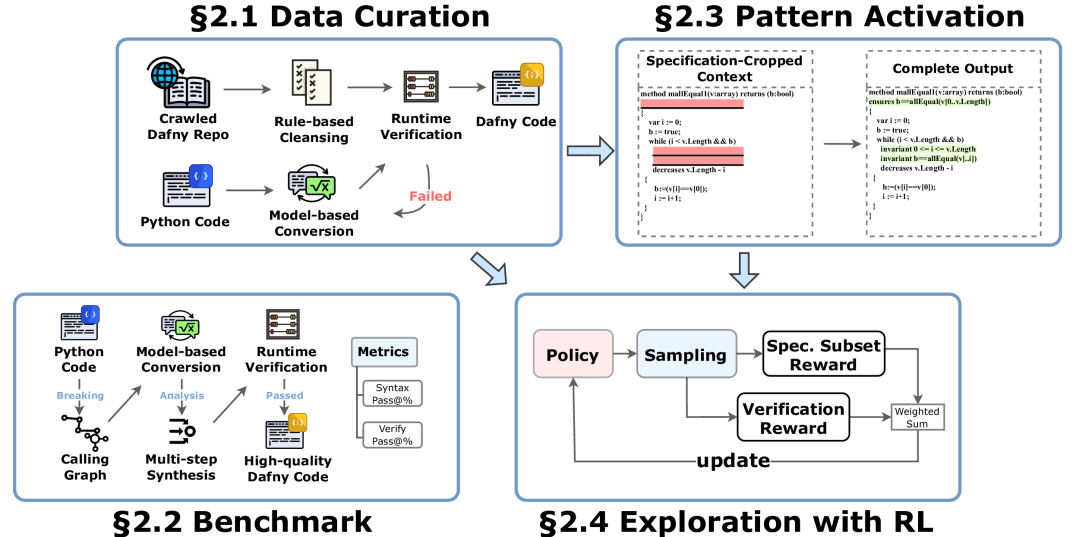
我们的目标是最小化人类先验知识,并依靠强化学习进行开放式探索,无需直接人类监督即可发现新的解决方案。
为此,我们首先采用前沿大语言模型自动生成形式化规范,为训练数据提供初始种子,并期望强化学习后续能够逐步提升解决方案的质量。鉴于形式化验证所需的中间推理步骤缺乏明确模板,我们随后移除了流程中的自然语言思维链。
最终,强化学习基于世界信号或系统代理进行反馈:通过完全在形式语言空间中操作,将自然产生一个自动评估信号,即为形式化陈述的正确性。
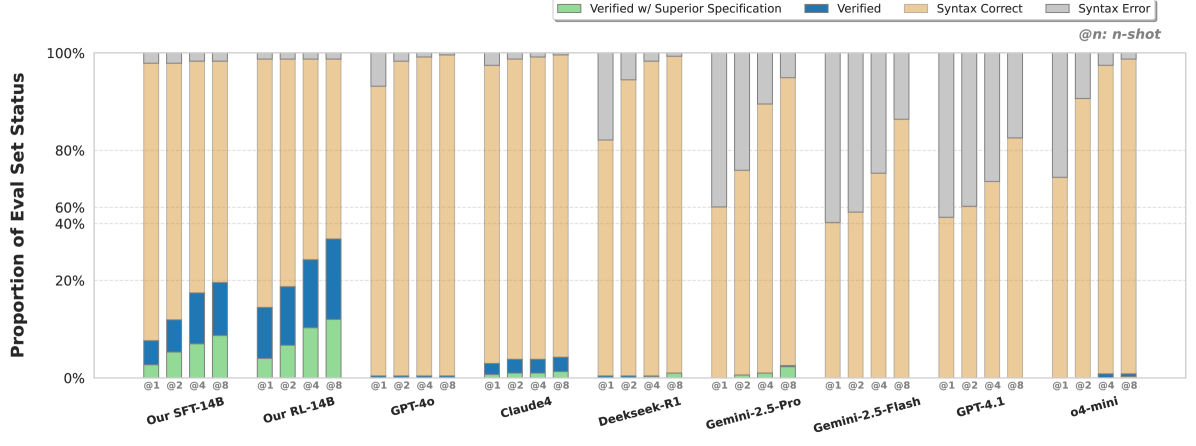
实验结果
本任务中,每段代码呈现出一个独特的形式化挑战,由其内在的隐式约束和逻辑结构决定。在最少的指导下,模型需深入理解任意代码片段并推断其形式化规范。为严格评估学习,我们引入了一种新的指标来衡量规范的质量,并提供了一个专为组合泛化评估而设计的综合基准。
实验结果验证了所提出“最小先验+强化学习”框架的可行性:该智能体促进了有效探索,从种子数据中获得了重要提升,并在域外性能中展现出显著优势。