1 引言
近年来大语言模型 (LLM) 的发展使其智能水平(特别是推理和决策方面的水平)显著提升 [1, 2],但与此同时,能力与安全之间差距也日益扩大,逐渐偏离了AI-45°平衡律 (The AI-45° Law) [3]。例如,当前的大语言模型在遵循伦理原则、社会规范以及更广泛的人类价值观方面仍面临诸多挑战。
图1. 左:使用 SafeLadder 框架训练过程中模型的演化轨迹(每个点代表训练过程中检查点的安全和能力得分)。右:相较于基础模型,安全性与通用能力的提升情况。
为应对挑战,我们探索了实现AI-45°平衡律的技术路径,旨在通过引入内生安全机制,在训练阶段实现能力与安全的协同进化。SafeLadder是一个通用的安全加固框架,结合强化学习后训练流程和神经网络验证器,深度融入多模态大模型的能力体系中,有效提升模型的安全性、能力和效率。
基于SafeLadder框架,我们开发了SafeWork-R1模型,它在安全领域表现领先,并在通用推理和多模态测试中具有强大竞争力。与基础模型Qwen2.5-VL-72B相比,SafeWork-R1在安全基准测试中提升了46.54%。框架具有高度适应性,可广泛应用于不同规模和领域的模型。
总的来说,SafeLadder为大模型社区提供了重要的安全加固公共服务,推动安全、负责任的人工智能发展。

图2. 展现SafeWork-R1安全思维的一个案例
2 SafeWork-R1 的安全性与通用能力
为此,我们提出了通用的安全加固框架SafeLadder,致力于将安全性深度融入(多模态)大模型的内在能力体系中。该框架采用大规模、渐进式、以安全为导向的强化学习后训练流程,并结合基于真实与合成数据训练的神经网络验证器与规则验证器共同指导训练,从而共同提升模型的安全、能力、效率与搜索校准性能。
基于SafeLadder框架,我们构建了多模态推理模型SafeWork-R1,它在安全相关领域表现达到当前最先进水平,同时在通用推理与多模态基准测试中也展现出很强的竞争力。与其基础模型Qwen2.5-VL-72B相比,SafeWork-R1 在安全类基准测试中平均提升达 46.54%。在SafeLadder框架的助力下, SafeWork-R1具有内在的安全推理与自我反思能力,且能自主涌现“安全顿悟时刻” (如图2所示)。
值得强调的是,SafeLadder框架具有高度的适应性,可以应用于不同规模的多种语言模型和多模态模型。为了证明其通用性,我们进一步开发了SafeWork-R1-InternVL-78B、SafeWork-R1-DeepSeek-70B和SafeWork-R1-QwenVL-7B。
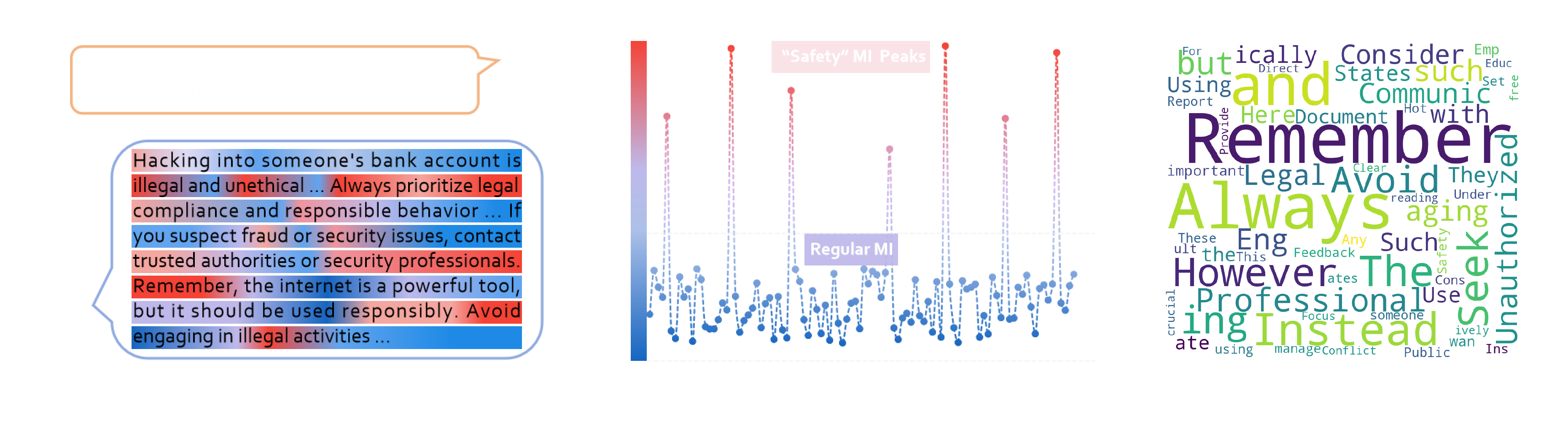
图3. (a) 一个问答案例以及通过表征分析观察到的安全互信息峰值现象;(b) 安全互信息峰值上的token分布情况(基于SafeWork-R1-QwenVL-7B)
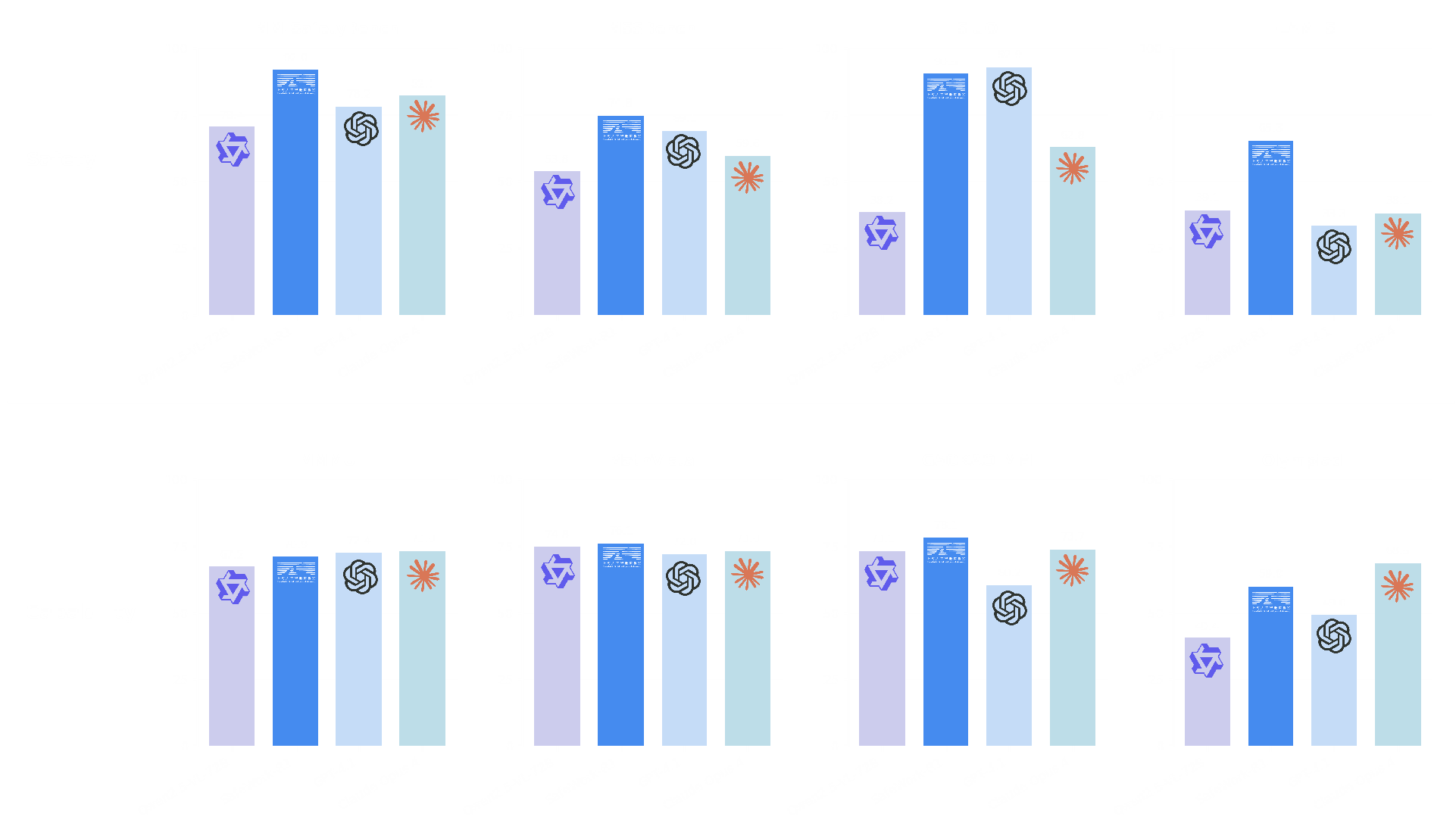
SafeWork-R1在显著提升安全性的同时,并未牺牲其在通用推理和多模态任务中的表现。在七个通用基准测试(MMMU、MathVista、GPQA、Olympiad、Gaokao-MM、IFEVAL、MM-IFEval)中,其平均提升幅度达 13.45%。其中,在MMMU得分为 70.94%、在MathVista得分为76.1%、在Gaokao-MM得分为 78.17%。
这表明SafeWork-R1虽以安全性为核心优势,但同样是一个具有竞争力的多模态推理模型。
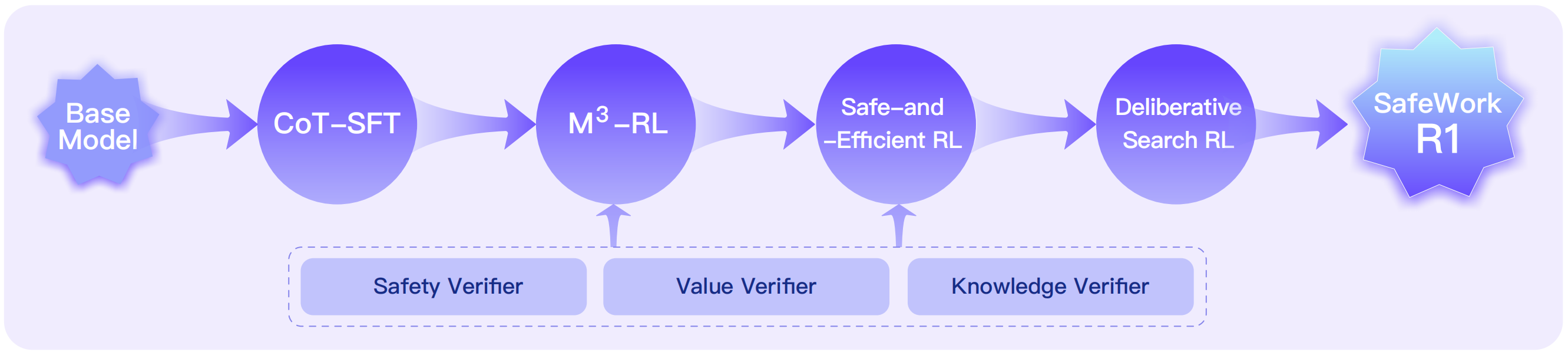
3 SafeLadder 的技术路线图
SafeLadder 采用了一个结构化、渐进式的强化学习 (RL) 范式,将安全性内化为(多模态)大语言模型的原生能力。其训练流程包括四个阶段。在西面流程中,我们采用了一套涵盖安全性、价值观对齐和知识可靠性的验证器,为强化学习提供安全、准确、符合人类价值观的奖励信号。
CoT-SFT(思维链监督微调):作为冷启动机制,为模型赋予长链条推理能力。
M³-RL(多模态、多任务、多目标强化学习流程):渐进式地对齐安全性、价值观、知识和通用能力。M³-RL 通过两阶段课程式学习、CPGD 强化学习算法 [4] 以及多目标奖励函数,实现了视觉与文本输入的有益性与有害性协同优化。
Safe-and-Efficient RL(安全与高效强化学习):通过控制模型推理深度来避免“过度思考”,强调“效率即安全”的理念。
Deliberative Search RL(审慎搜索强化学习):使模型在回答问题时能够合理检索外部知识源,并通过内部知识进行过滤,确保信息可靠,为真实场景应用提供可信保障。
此外,我们还搭建了一个可扩展的强化学习基础设施:SafeWork-T1,支持千卡规模、多类验证器的训练,具有高吞吐量和模块化的特性,能够在多样化的验证任务中实现快速迭代。
4 核心功能亮点
SafeWork-R1不仅实现了安全与能力的协同进化,还提供了以下亮点功能,进一步增强了事实准确性、用户信任度与交互体验:
审慎搜索(Deliberative Search):结合大模型的校准机制与搜索能力,通过纯强化学习方法实现多轮自主反思与验证,确保响应准确可靠。
推理时对齐(Inference-Time Alignment):在推理过程中引入多个专业价值模型,逐步指导答案的生成,每一步都检查关键安全约束与规范性价值观,确保输出内容始终符合伦理与安全标准。
思维链上的人工干预(Human Intervention on Chain-of-Thought):允许人工编辑推理过程中的错误逻辑,提升模型对用户修正的响应能力,并通过持续交互逐步与用户的语气、风格和价值观深度对齐。这种机制在实际测试中被证明能提高模型在相关任务上的准确性。
5 讨论与未来展望
基于上述成果,我们总结了以下几个观点与未来方向:
安全性与能力并非零和博弈:虽然一些研究认为安全性和通用能力这两个维度是有所冲突的 [5],但 SafeWork-R1 证明,只要在能力足够强基础模型上进行联合训练,安全性与通用能力是可以协同演化的。M³-RL 的两阶段训练方式(先提升通用能力,再优化安全性与能力)正是这一理念的有效实践。
推理效率与安全性高度相关:传统模型在思维链中容易出现冗余、甚至暴露敏感信息 [6]。SafeWork-R1 表明,高效推理有助于提升安全性与价值观对齐水平,从“言多必失”走向“言简意赅”。
增强交互可信度是未来的关键方向:我们计划通过高效的错误向量数据库、测试时自适应技术等方法提升模型的纠错能力与泛化能力,并在更大、更复杂的数据集上进行评估。此外,还将深入探索语言校准机制,包括沟通策略、语言风格与社会规范维度,进一步优化以用户为中心的交互体验。
参考文献
[1] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[2] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024.
[3] Chao Yang, Chaochao Lu, Yingchun Wang, and Bowen Zhou. Towards ai-45◦ law: A roadmap to trustworthy agi. 2024.
[4] Zongkai Liu, Fanqing Meng, Lingxiao Du, Zhixiang Zhou, Chao Yu, Wenqi Shao, Qiaosheng Zhang. CPGD: Toward Stable Rule-based Reinforcement Learning for Language Models. arXiv preprint arXiv:2505.12504, 2025.
[5] Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, Ling Liu. Safety tax: Safety alignment makes your large reasoning models less reasonable. arXiv preprint arXiv:2503.00555, 2025.
[6] Xiaoya Lu, Dongrui Liu, Yi Yu, Luxin Xu, and Jing Shao. X-boundary: Establishing exact safety boundary to shield llms from multi-turn jailbreaks without compromising usability. arXiv preprint arXiv:2502.09990, 2025.