| Code: https://github.com/Veri-Code/ReForm |
| Models & Data: https://huggingface.co/Veri-Code |
Background
Autoformalization (converting natural language content into verifiable formalization) is considered a promising way of learning general purpose reasoning. In sharp contrast, existing natural language-based LLMs lack reliable verification.
Formal verifiers are not only important for increasing the resiliency of humanity, but also vital for steering artificial intelligence (AI) development into a direction of maximally “math-seeking,” which could be, hopefully, more human-friendly and realistic.
Although formal verification is usually extremely hard to obtain, recent progress in automated reasoning could potentially make this approach easier.
However, existing large language models (LLMs) cannot do genuine logical reasoning or self-verification on their own, and they should be viewed as universal approximate knowledge retrievers. Given the important role of formal verifiers, we hope to explore ways of scaling them up.
Coding agents draw attention in the AI community amid claims that their emergent problem-solving abilities may foreshadow broader general intelligence.
Despite the impressive progress in automated code generation due to recent advances in LLMs, ensuring the correctness of such code remains a significant challenge — especially in safety-critical domains such as healthcare, finance, and autonomous systems. Traditional safeguards such as unit testing or manual code review are inherently limited: they may miss edge cases, fail to cover all execution paths, or rely heavily on human expertise.
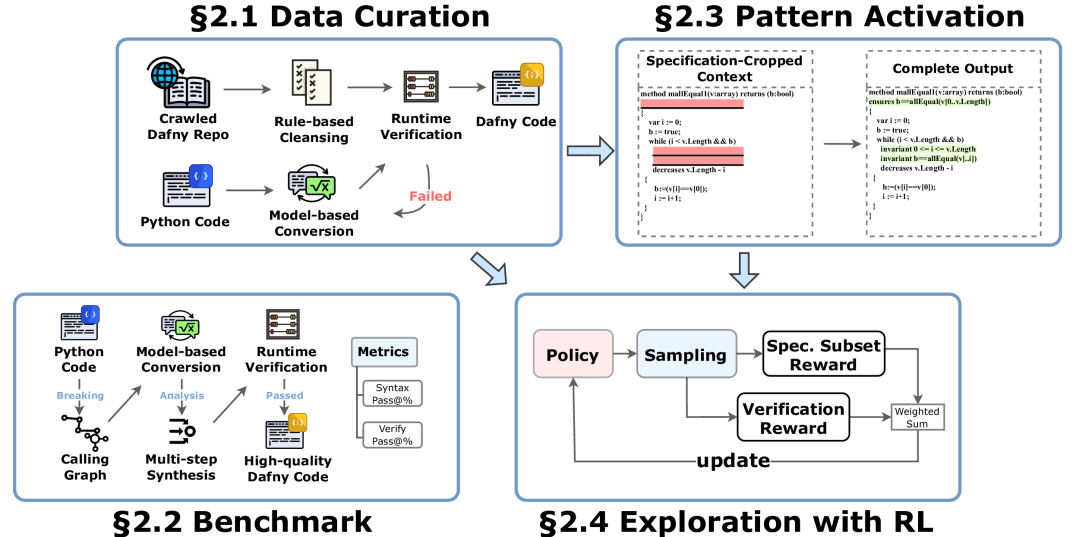
Instead, formal verification offers a principled alternative. Therefore, we propose to independently auto-formalize the natural language query and the code, and then verify their derived specifications’ equivalence, to guarantee behavioral alignment. We target a challenging subproblem: the formal specification generation, requiring deep semantic understanding and exhaustive behavioral description of arbitrary code.
Core Designs
We aim at minimizing human priors and relies on reinforcement learning (RL) for open-ended exploration, uncovering novel solutions without direct human supervision.
First, we automatically generate formal specifications using proprietary frontier LLMs to seed our training data, anticipating RL to progressively improve solution quality.
Next, lacking a clear template for the intermediate reasoning steps needed in formal verification, we have chosen to eliminate natural-language chain-of-thought (CoT) from our pipeline.
Finally, our RL feedback comes from world signals or system proxies: by operating entirely in a formal-language space, an automatic evaluation signal naturally emerges, which is the correctness of formal statements.
Experimental Results
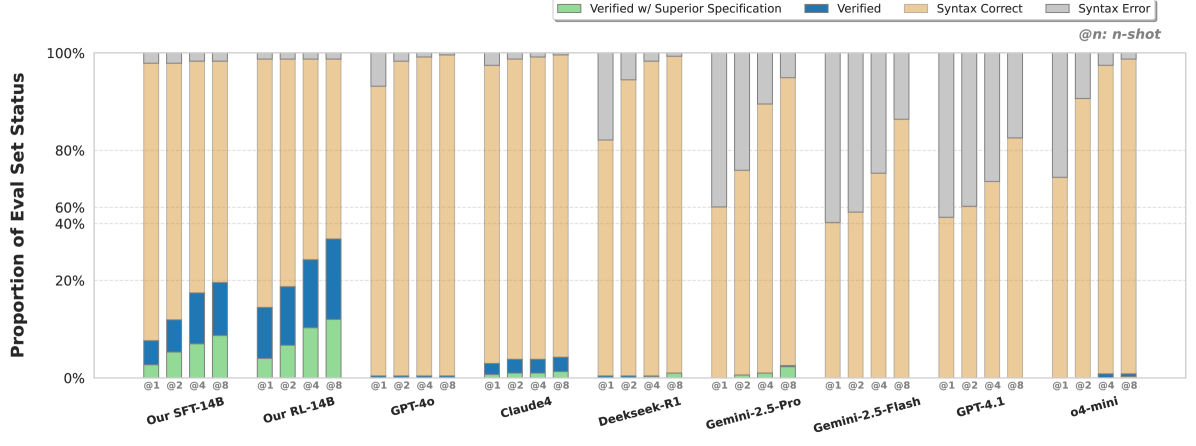
In our task, each piece of code presents a unique formalization challenge, shaped by its own implicit constraints and logical structure.
Faced with minimal guidance, our model must deeply understand arbitrary code snippets and infer their formal specifications. To rigorously assess learning, our task introduces a novel metric to measure the specifications’ quality and provides a synthetic benchmark tailored to the compositionality generalization evaluation.
Our results validate the viability of our minimal-prior + RL framework: the agent indeed fosters effective exploration, leading to meaningful improvement from the seed data and dominating in out-of-domain performance.