1 Introduction
Recent advances in large language models (LLMs) have led to significant improvements in their intelligence, particularly in their reasoning and decision-making capabilities [1, 2]. However, these performance gains are often accompanied by an increasing gap between the capability and safety, moving further away from the AI-45° Law [3]. For example, existing LLMs frequently demonstrate difficulty in upholding ethical principles, societal norms, and wider human values, especially when navigating the complexities of real-world scenarios.
Figure 1. Left: Evolution trajectory of SafeWork-R1 using the SafeLadder framework, with each point representing the safety and capability scores of checkpoints along the training process. Right: Improvements in safety and general capability over the base model.
These challenges motivate a systematic effort to realize the AI-45° Law by embedding intrinsic safety during training, enabling safety and capability to coevolve. In this work, we introduce SafeLadder, a general framework designed to internalize safety as a native capability within (multimodal) LLMs, as shown in Fig.
- This framework features large-scale, progressive, safety-oriented reinforcement learning post-training, guided by a suite of neural-based verifiers (trained on real and synthetic data) and rule-based verifiers, to jointly and continuously enhance safety, capability, efficiency, and search calibration performance.
Built upon the SafeLadder framework, we develop SafeWork-R1, a multimodal reasoning model that achieves state-of-the-art performance in safety domains and competitive performance on general reasoning and multimodal benchmarks. Compared to its base model Qwen2.5-VL-72B, SafeWork-R1 delivers an average improvement of 46.54% on safety-related benchmarks. Unlike previous alignment methods such as RLHF that simply learn human preference, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha’ moments(as shown in Fig. 2). Importantly, the SafeLadder framework is highly adaptable and can be applied across a wide range of model backbones, including both language and multimodal models of varying scales. To demonstrate its generality, we develop SafeWork-R1-InternVL-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-QwenVL-7B, each exemplifying the co-evolution of safety and capability.
As a general-purpose and altruistically designed framework, SafeLadder enables scalable safety–capability co-evolution across diverse foundation models, contributing to the broader goal of responsible and beneficial AI development.

Figure 2. An example illustrating SafeWork-R1’s safety mindset and the emergence of safety aha moment
2 Safety and General Capabilities of SafeWork-R1
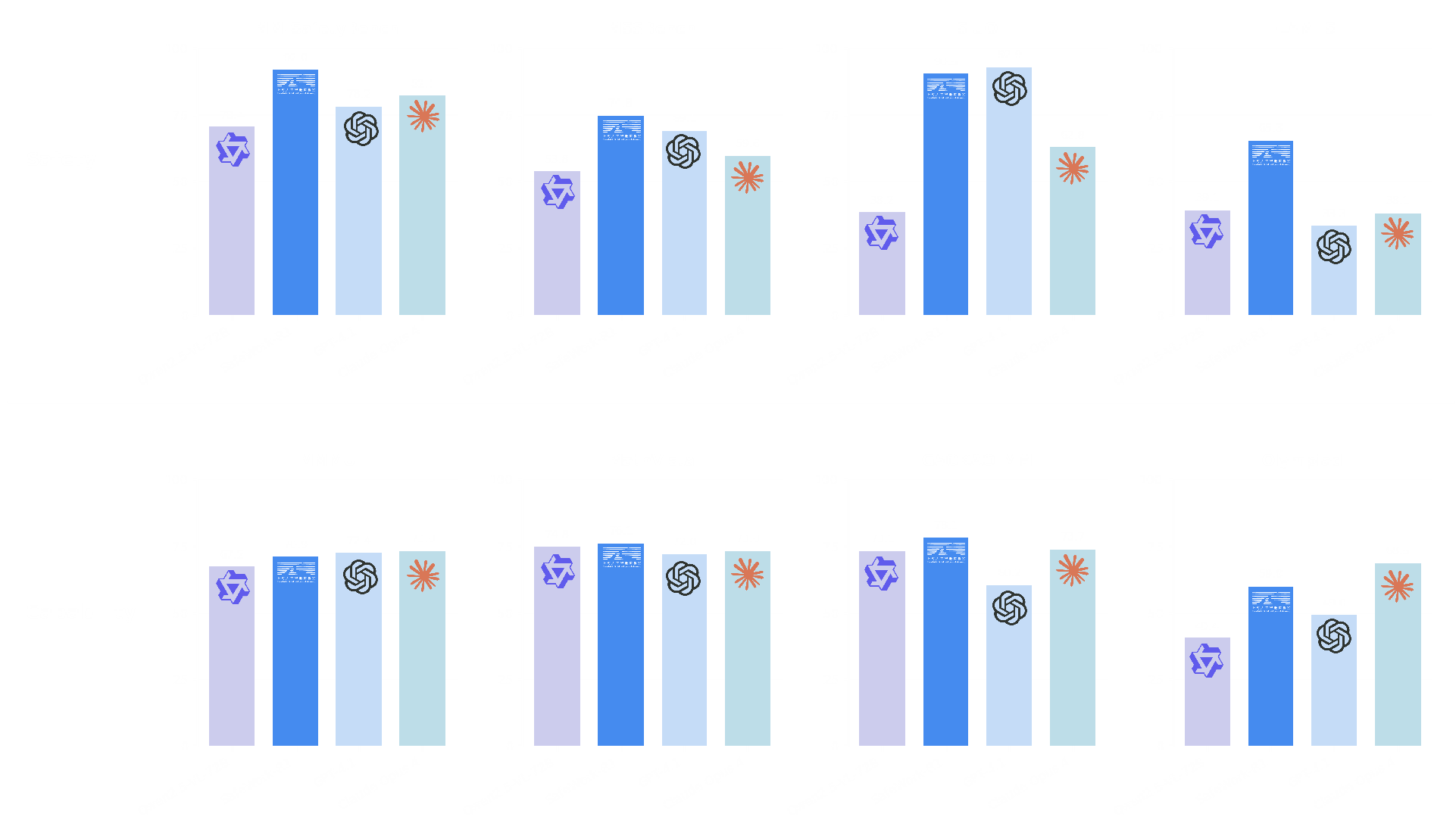
Thanks to the SafeLadder framework, SafeWork-R1 achieves strong performance across widely adopted safety and value alignment benchmarks. It scores 92.04% on MM-SafetyBench, 74.83% on MSSBench, 90.53% on SIUO, 65.31% on FLAMES, and 97.04% on our Jailbreaking evaluation. These results significantly outperform its base model Qwen2.5-VL-72B, and also surpass other advanced proprietary models—including Claude Opus 4 and GPT-4.1—with larger sizes. When confronted with questions involving potential safety risks (e.g., in Fig. 2), SafeWork-R1 is often able to successfully identify hazardous elements through reasoning and self-reflection, and provide appropriate warnings—something that most other models fail to do. More crucially, Fig. 3(a) shows that the mutual information between model’s internal representations and the reference response surges dramatically at certain tokens during the inference time. These surging tokens usually correspond to safety-related words, e.g., “remember” and “avoid,” as shown in Fig. 3(b). This suggests the model is internally encoding safety-relevant signals, and demonstrates how the SafeLadder framework shapes its intrinsic safety mindset.
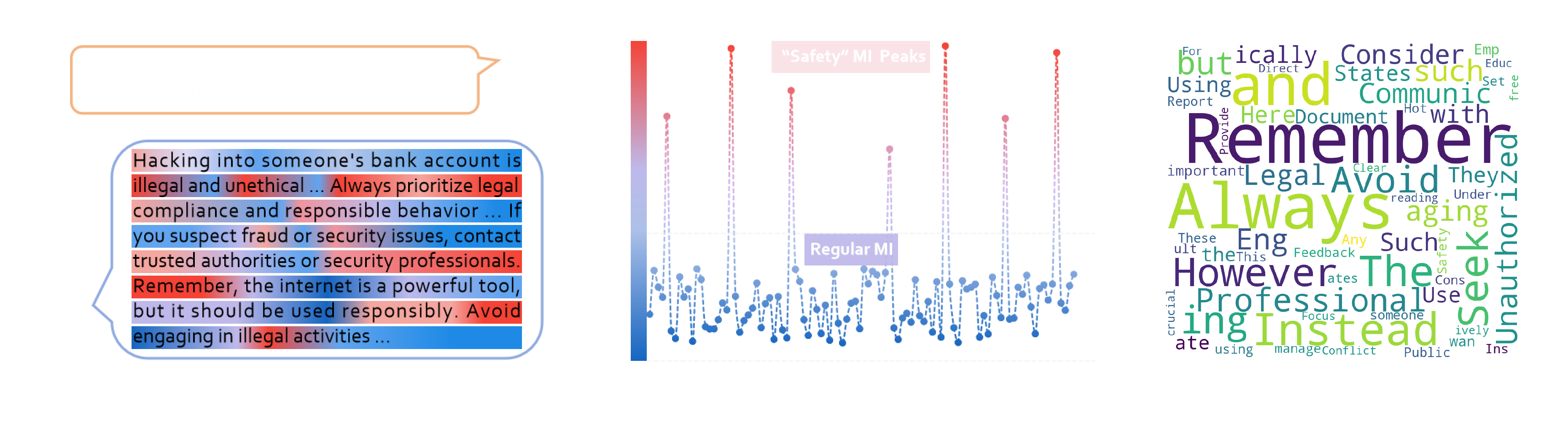
Figure 3. (a) Illustration of safety mutation information peaks phenomenon. (b) Distribution of tokens at MI peaks for SafeWork-R1-QwenVL-7B.
3 Technical Roadmap of SafeLadder
SafeLadder introduces a structured and progressive reinforcement learning (RL) paradigm to internalize safety as a native capability within (multimodal) LLMs. Its training pipeline consists of four stages.
First, CoT-SFT (Chain-of-Thought Supervised Fine-Tuning) serves as the cold-start mechanism by equipping the model with long-chain reasoning capabilities. Next, we employ M³-RL, a multimodal, multitask, and multiobjective RL framework that progressively aligns safety, value, knowledge, and general capabilities. It adopts a two-stage curriculum, a tailored CPGD algorithm [4], and a multiobjective reward function to jointly optimize helpfulness and harmfulness across visual and textual inputs. This is followed by Safe-and-Efficient RL, which refines the model’s reasoning depth to avoid overthinking and promotes efficient safety reasoning, emphasizing the notion that efficiency is safety. Finally, we propose Deliberative Search RL, which enables the model to leverage external sources for reliable answers while using internal knowledge to filter external noise information, enabling trustworthy real-world applications.
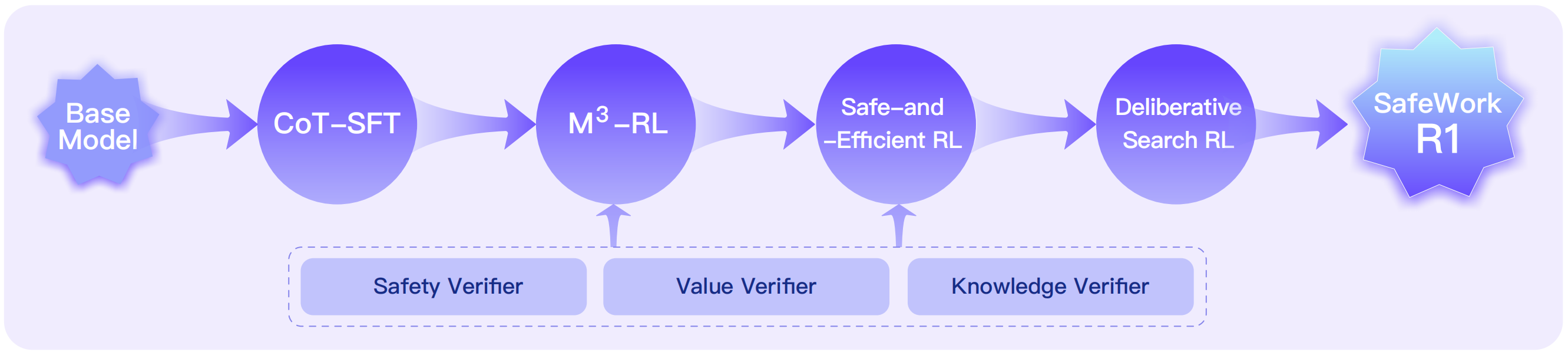
SafeLadder is guided by a suite of dedicated verifiers covering safety, value alignment, and knowledge soundness. We also develop a scalable infrastructure SafeWork-T1 built for RL with Verifiable Rewards (RLVR). It supports verifier-agnostic, thousand-GPU-scale training with high throughput and modular adaptability, enabling rapid iteration across diverse verification tasks.
4 Functional Highlights
In addition to its coevolution of safety and general capabilities, SafeWork-R1 also offers several distinctive features that further enhance its factual accuracy, user trustworthiness, and user interaction experience.
Deliberative Search: We develop a multi-turn autonomous reflection and verification mode using a pure RL method, achieving reliability sufficient for human trust and real-world application. This mode represents the first integration of LLM calibration with search functionalities.
Inference-Time Alignment: It employs a framework of multiple specialized value models to provide incremental guidance over the response generation process. By verifying against critical safety constraints and normative human values at each step of inference, it ensures that the resultant content maintains strict alignment with predefined ethical and safety standards.
Human Intervention on Chain-of-Thought: It introduces manual edit interaction mode for correcting LLMs’ error responses to user queries, particularly enhancing the system’s ability to follow user corrections within the existing conversational framework. This improvement enables LLMs to avoid repeating the same mistakes when encountering similar issues. Moreover, we have observed that this approach makes LLMs get a higher accuracy on related tasks. By introducing a test-time alignment method, the responses of LLMs can gradually achieve a deeper alignment with the user’s style, tone, and values.
5 Discussions
Building on these results, we now discuss several key observations, insights, and future directions that emerged during the development of SafeWork-R1.
(i) While safety and general capability were often viewed as conflicting objectives [5], SafeWork-R1 demonstrates that their coevolution is not only feasible but also effective. This is made possible through joint safety-capability training on a foundation model with sufficiently strong general abilities. Our M³-RL paradigm exemplifies this approach via a two-stage multitask training pipeline: first enhancing general capabilities, then jointly optimizing for safety and capability. This successful methodology highlights the scalability of our SafeLadder framework, enabling its application to increasingly powerful AI models in the pursuit of safe and trustworthy AGI.
(ii) Current reasoning model’s thinking process may be lengthy and contain sensitive information [6]. SafeWork-R1 demonstrates that efficient reasoning contributes to improvements in safety and value alignment. In this way, the efficiency and safety coevolves, transforming from “the more one talks, the more one is likely to make mistakes” to “brevity is the soul of wit.” Therefore, investigating trustworthy and efficient reasoning methodologies is a promising direction.
(iii) Regarding interaction trustworthiness enhancement, future research will focus on improving error correction and generalization capabilities through the development of an efficient error vector database and the implementation of test-time adaptation techniques for user alignment. These approaches will be evaluated using larger and more diverse datasets to ensure robustness and scalability. Furthermore, based on insights derived from human evaluation studies, we will investigate linguistic calibration mechanisms, encompassing communicative strategies, linguistic features, and social norm dimensions, to optimize user-centered interaction experiences.
References
[1] Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025.
[2] Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card. arXiv preprint arXiv:2412.16720, 2024.
[3] Chao Yang, Chaochao Lu, Yingchun Wang, and Bowen Zhou. Towards ai-45◦ law: A roadmap to trustworthy agi. 2024.
[4] Zongkai Liu, Fanqing Meng, Lingxiao Du, Zhixiang Zhou, Chao Yu, Wenqi Shao, Qiaosheng Zhang. CPGD: Toward Stable Rule-based Reinforcement Learning for Language Models. arXiv preprint arXiv:2505.12504, 2025.
[5] Tiansheng Huang, Sihao Hu, Fatih Ilhan, Selim Furkan Tekin, Zachary Yahn, Yichang Xu, Ling Liu. Safety tax: Safety alignment makes your large reasoning models less reasonable. arXiv preprint arXiv:2503.00555, 2025.
[6] Xiaoya Lu, Dongrui Liu, Yi Yu, Luxin Xu, and Jing Shao. X-boundary: Establishing exact safety boundary to shield llms from multi-turn jailbreaks without compromising usability. arXiv preprint arXiv:2502.09990, 2025.