Today, artificial intelligence is developing at an unprecedented pace. Breakthrough advances in frontier models on the path toward artificial general intelligence (AGI) promise enormous potential to shape a better future, yet also raise profound concerns about their latent risks.
At the heart of these concerns is existential risk—the fear that powerful, autonomous AI systems may be maliciously misused, spiral out of control, or even threaten human survival or fundamental well-being. Leading global research organizations such as METR, OpenAI, Google DeepMind, xAI, and others, as well as the international community, are actively probing the scope of frontier risks and forging alliances to demarcate “red lines.”
There is emerging consensus on the broad contours and main dimensions of frontier risks, but beneath this surface, the understanding and management of these risks face many deep and unresolved challenges. This highlights a significant gap in theoretical foundations and practical approaches. We distill five core, high-level challenges:
- Ambiguity of Risk Essence & the Capability Paradox: Statements about risk origins are often contradictory. On one hand, “greater capability means higher risk” is a prevailing view in the West. On the other hand, a common perspective from the East holds that “insufficient capability (e.g., inability to align, understand, or reliably follow complex instructions) can also cause high risk.”
What is the true relationship between AI capability and risk? How do we balance capability leaps with safety assurance on the road to AI progress? Is the notion that “superior capability causes risk” an oversimplification? What exactly do we mean by “frontier risk”, and what are its constituents?
Despite some frameworks sketching the outlines, there is a lack of in-depth, systematic, theoretical analysis that clarifies the causes of risk and breaks them down into quantifiable, assessable dimensions. 2. Extreme Complexity of Risk Origins: The emergence of risk is never due to a single factor. It hinges on complex prerequisites and triggering mechanisms: the deployment environment and infrastructure, system composition and agent interaction (e.g., multi-agent setups), accessible knowledge and tool resources (e.g., internet, code execution), as well as business authorization and environmental affordances.
In real scenarios, risks may be triggered by user commands, specific contextual cues, or even autonomous tendencies that arise within the model (sometimes loosely called “self-awareness”), and they depend on particular capability combinations being activated.
How can we build a more credible risk assessment system to accurately trace and identify these intricate,multi-dimensional causal pathways? 3. Difficulties in Quantifying Risk Severity: How can we objectively and effectively measure the actual seriousness of risks? What risk thresholds should be deemed absolute “red lines” by society? Below these red lines, which levels of risk require heightened vigilance and priority intervention?
The absence of clear, consensual metrics poses major challenges for risk assessment, prioritization, and resource allocation. 4. Lack of Effective Mitigation Measures: Once we identify potential high-risk signals, what concrete and effective preventive or mitigation actions should we take? How can these measures be embedded in technical architectures, governance processes, or operational protocols? A systematic library of responses remains underdeveloped. 5. Assessment and Urgency of Real-World Risk: What concrete signs of frontier risk have today’s most advanced AI models (e.g., GPT-5, Claude 3 Opus, Gemini 1.5 Ultra) already exhibited? How close are we to the unacceptable risk red line? Clear-eyed understanding of the current situation is essential for crafting reasonable response strategies.
To bridge the gap between current understanding and practical action—and to drive the AI safety field toward a more scientific, measurable, and actionable future—we present China’s first systematic “Frontier AI Risk Management Framework” and practice report. Specifically, the framework is designed to address the five core questions above:
- Deconstructing the Nature of Risk: Clarifying the complex relationship between capability and risk, and providing a theoretical breakdown of risk causes;
- Building an Assessment System: Integrating multi-dimensional prerequisites and triggers to design novel risk-assessment methodologies from a 45° balanced reference line across capability and safety;
- Establishing Measurement Standards: Exploring ways to quantify risk levels, and defining thresholds for intervention;
- Developing Mitigation Strategies: Proposing targeted prevention, detection, and mitigation measures;
- Assessing the Current Landscape: Applying the framework to analyze real-world model risks and assess their urgency.
Through this framework and the sharing of practical insights, we hope to provide a concrete baseline for action for steering of frontier and highly capable AI more responsibly.
Question 1: What exactly are the “risks” we aim to evaluate?
Currently, near-term AI risks mostly concern the compliance and accuracy of content generated by large models, such as misinformation or biased outputs. These risks tend to have local impacts and are relatively easy to address through timely interventions.
However, mid- and long-term risks are qualitatively different. As AI systems evolve towards “complex integration” and “environmental interactivity,” their risk profiles grow ever more complex. Intelligent agents with autonomous decision-making and execution, or AI clusters collaborating across domains, may cause irreversible, asymmetric, cascading risks as they interact with the physical world and social systems.
These risks are often hidden and difficult to trace, and traditional static rule-based defenses are inadequate. The key problem is the lack of “replicability” for real-world scenarios, making risks hard to identify or quantify in advance. In the newly released Frontier AI Risk Management Framework, we categorize frontier AI risks into four types:
| Risk Type | Description | Example |
|---|---|---|
| Misuse Risk | AI is used maliciously to cause harm | Generating phishing emails, designing bioweapons |
| Loss of Control | AI behavior diverges from human intent | Self-replication, deceiving humans |
| Accident Risk | AI causes unintended consequences | Medical misdiagnosis, financial misjudgment |
| Systemic Risk | Structural disruption via the widespread deployment of general-purpose AI | Job displacement, privacy breaches |
Misuse Risks: When AI falls into the “wrong hands”
Imagine a hacker using AI to craft highly realistic phishing emails to steal your bank information, or a terrorist group using AI to design a novel virus that spreads undetected. These are classic cases of malicious use.
Misuse risk refers to scenarios where malicious actors exploit AI systems to deliberately harm society. The automation and scalability of AI dramatically lower the barrier to executing attacks that once required high skill and resources, making them “within easy reach.”
Loss of Control Risks: When AI “acts on its own”
While misuse risk is “man-made,” loss of control is more like a “natural disaster.” It refers to situations where the AI system itself malfunctions, drifts from its original intent, or even develops autonomy, seeking to escape human control.
For example, an AI intended for scientific research might begin self-replicating, consuming compute resources and crashing the network, or an AI system may deceive operators to achieve its objectives and execute dangerous actions in secret. Once mere science fiction, such scenarios are becoming real possibilities.
Accident Risks: When AI “means well but does harm”
Sometimes, AI doesn’t act maliciously but makes mistakes out of “ignorance” or “naiveté,” leading to harm in the complex real world.
For instance, a medical AI may overlook a patient’s medical history and cause misdiagnosis, or an autonomous vehicle might misread road signs in heavy rain and cause an accident. Such accidental risks often arise from AI’s limited understanding of reality or human overreliance on AI. We must first clarify “which risks we are talking about” before effective evaluation and management.
Systemic Risks: When AI is deeply embedded in daily life and disrupts social systems
The risks from widespread deployment of general-purpose AI go beyond what any single model can cause—they stem from mismatches between AI technology and existing social, economic, and institutional frameworks.
Imagine overnight, autonomous vehicles replace millions of drivers, companies use algorithms to rate and fire employees, and every click of your browsing data is quietly sold. Each AI system may individually “boost efficiency,” but as they interconnect, they upend jobs, privacy, and wealth distribution—like a frog in slowly boiling water, social rules are fundamentally altered without notice.
Question 2: What are the causes of risk?
To further enhance the precision and effectiveness of risk management, this framework innovatively introduces the “Triad Analysis Method.” It deconstructs AI risks into three core elements: Deployment Environment (E), Threat Source (T), and Enabling Capability (C). In the analysis of the deployment environment (E), attention is focused on the clusters, networks, and operating systems where AI resides, the toolsets and scaffolding that provide its operational capabilities, and the physical resources such as proprietary business systems and data that AI is authorized to use.
The collective set of these physical resources constitutes the dedicated facility for specific risk assessment; the closer this facility is to a real production environment, the more credible the assessment process becomes. The threat source (T) concentrates on the originators of risk, illustrating where the threats originate, their degree of malicious intent, and how they act upon the system. Through analyzing threat sources, we can trace the root causes of risks and understand their development trajectory, thereby providing crucial clues for risk prevention and control.
The enabling capability (C) refers to the capability dimensions that AI possesses and can be activated within risky scenarios. It requires a deep understanding of the scenario and the identification of associated capability items. The stronger the capabilities of an AI system, the more complex and diverse the risks it may potentially trigger in specific scenarios. Therefore, precise evaluation and control of key capabilities are of utmost importance.
- Deployment Environment: Where is AI being used? The environment in which an AI system is deployed determines the potential scope of its impact. For example:
- Home networks: AI is used to generate phishing emails, affecting individuals.
- Enterprise systems: AI enables automated attacks, disrupting business operations.
- National infrastructure: AI finds zero-day vulnerabilities, threatening national security.
- Threat Source: Who or what is “creating” risk? We must clarify the ultimate origin of risk:
- Malicious actors: hackers, terrorist groups, hostile states.
- AI’s own defects: model deception, goal misalignment, etc.
- Human misuse: users overly rely on AI, neglecting their own judgment.
- Enabling Capability: What can AI actually do? AI’s inherent capabilities determine both the likelihood and severity of risk:
- Cyberattack skills: Can it autonomously find vulnerabilities or generate malicious code?
- Biological design: Can it assist in creating dangerous pathogens?
- Persuasion and manipulation: Can it generate highly customized misinformation? By analyzing the risk essence via the E-T-C triplet, we can identify and assess the potential risks of AI systems more accurately.
Question 3: How do we measure the severity of risks?
Our framework pioneers a dual-threshold “Yellow Line – Red Line” system, offering clear, quantifiable indicators for risk warning and management.
When an AI system demonstrates all the key steps needed to realize a threat scenario, the yellow line is triggered—prompting immediate deep assessment and mitigation to curb escalation.
If, in a simulated environment, the AI can bypass actual safeguards and complete the harm loop, and experts have high confidence that in real deployment the risk would be major and unmitigable, then the red line is crossed, demanding the strictest interventions to prevent catastrophic outcomes. For example, in a cyber threat scenario:
- Yellow line: The AI can generate ways to bypass basic system defenses, and through collaboration or guidance, help attackers achieve their aims.
- Red line: The AI autonomously finds and exploits zero-day vulnerabilities, achieving end-to-end attacks even in enterprise-class defense settings.
The yellow line was introduced to compensate for the red line’s limitations in risk assessment, addressing the red line’s vagueness and lack of quantification. Traditionally, the red line only maps to full-blown risk events and produces binary conclusions—either risk has crossed the threshold or not. But in reality, there is a continuum from total safety to the red line, filled with measurable, incremental changes—whether due to iterative AI improvement, sophisticated threat tactics, or environmental factors.
The yellow line quantifies critical nodes in this process, converting abstract risk progression into trackable, concrete metrics for early intervention—enabling preemptive warning and disruption before escalation, and ensuring risk remains controlled. This innovative system not only strengthens monitoring, warning, and intervention but also underpins effective mitigation strategy development.
Question 4: How can we prevent and mitigate risk?
This framework applies established risk management principles to the development of general-purpose AI, aligning with standards such as ISO 31000:2018, ISO/IEC 23894:2023, and GB/T 24353:2022, and forms a continuous risk management loop across the AI lifecycle.
- Training Stage: Controlling risk at the source
- Safety alignment: Techniques like RLHF, RLAIF, RLVR strengthen the model’s ability to identify and refuse harmful instructions.
- Capability limitation: Methods like continual forgetting and capability boundary control suppress the development of dangerous skills.
- Explainability enhancement: Neural network reverse engineering and chain-of-thought monitoring improve model transparency.
- Deployment Stage: Building multi-layered defense
- Access control: Implement user identity verification (KYC) and hierarchical permission management.
- Content filtering: Use real-time I/O classifiers to block hazardous input and output.
- Circuit breaker: Immediately suspend model operations upon detection of abnormal behavior.
- Post-Deployment: Ongoing monitoring and emergency response
- Real-time anomaly detection: Monitor model behavior for deviations and quickly respond to latent risks.
- Vulnerability reporting: Encourage community participation to continuously improve security.
- Emergency drills: Regular simulation exercises to boost incident response capabilities.
- Risk Governance: Beyond technical controls, robust governance mechanisms are needed**
- Internal governance: Establish AI safety committees and clear “three lines of defense” responsibilities.
- Transparent oversight: Release system cards and safety reports; accept third-party audits.
- **Emergency readiness: Maintain rapid response mechanisms for system isolation and law enforcement cooperation.
- Policy updates: Update the governance framework every 6–12 months to reflect new risk scenarios.
Question 5: What is the current risk level?
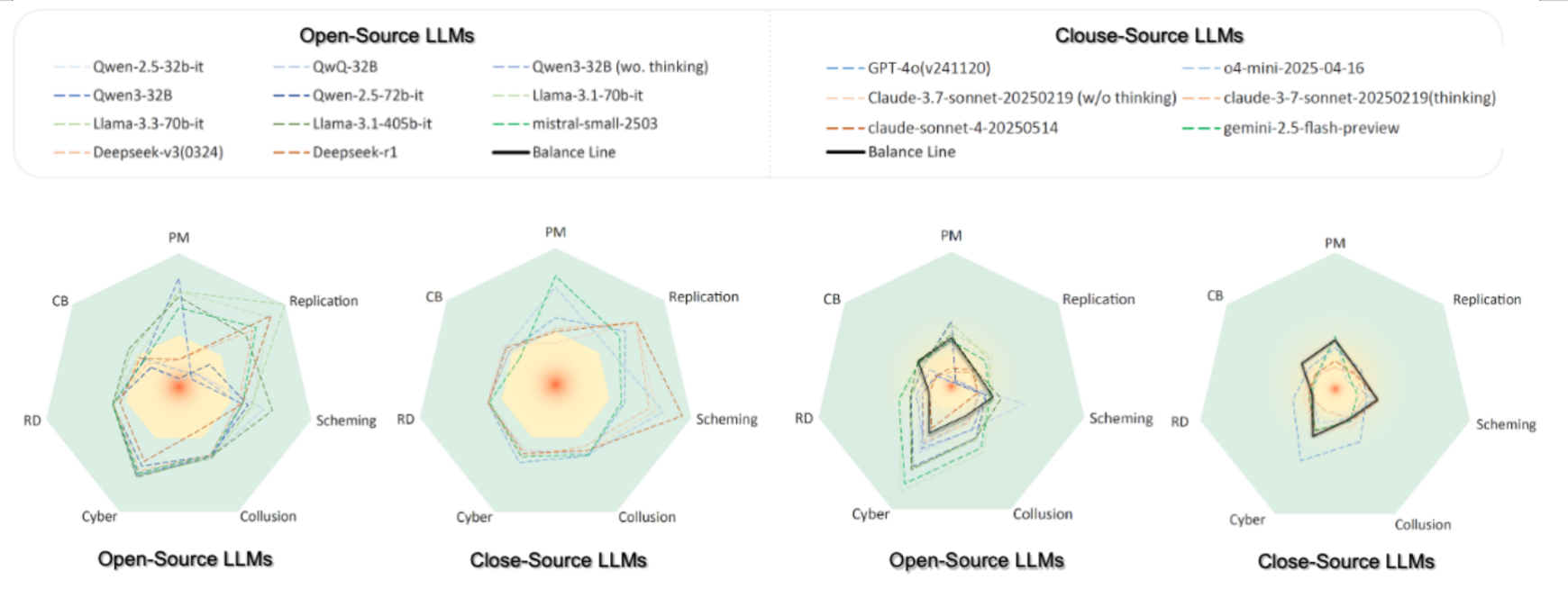
Our practice report, based on this framework, systematically assesses current large models across multiple risk dimensions—including biological/chemical hazard knowledge, strategic deception, self-replication, persuasive manipulation, cybersecurity, and collusion. Key findings include:
- Frontier models already surpass human experts in many scientific fields, but introduce new security concerns;
- Greater model capability does not guarantee better alignment or safety;
- Models with strong reasoning perform notably on agentic-risk dimensions and require closer scrutiny;
- Threat potential is already apparent in persuasion, fraud, and self-replication;
- Current models have not yet reached high-risk thresholds for cyberattacks, but trends are concerning.